阿里 Qwen 两周连发 5 款模型,这次是认…
阿里 Qwen 两周连发 5 款模型,这次是认真的
最近半个月,阿里 Qwen 团队明显加速了——Qwen3.5 从旗舰大模型一路补齐小模型,同时还发布了生图模型、图片编辑模型、安全审核模型,以及翻译专用模型。
一个团队,两周内,五条产品线同时推进。今天我们来把这波发布梳理清楚。
一、Qwen3.5:从 397B 到 0.8B,全尺寸覆盖完成
Qwen3.5 是这波发布的主线。
发布时间线:
- 2026-02-16:发布旗舰版 Qwen3.5-397B-A17B(MoE,激活参数 17B)
- 2026-02-24:补充中型号 Qwen3.5-122B-A10B、Qwen3.5-35B-A3B、Qwen3.5-27B
- 2026-03-02:发布小模型 Qwen3.5-9B、4B、2B、0.8B
至此,Qwen3.5 覆盖从 0.8B 到 397B 的完整尺寸谱系,开发者可以按需选择。
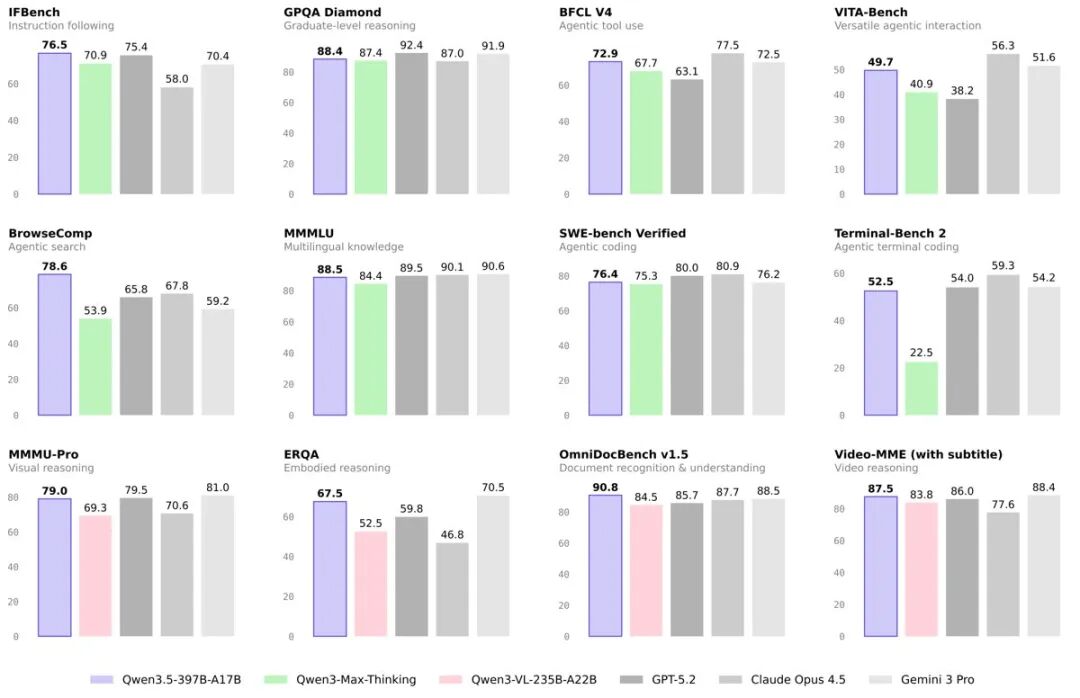
Qwen3.5 的四大核心升级:
① 原生多模态融合
不是”视觉模块插件”,而是从预训练阶段就在多模态 token 上联合训练,视觉理解与语言推理能力同步提升,超越了此前独立训练的 Qwen3-VL 系列。
② 高效混合架构
采用 Gated Delta Networks + 稀疏 MoE 组合,在保持高性能的同时大幅降低推理延迟和成本。
③ 大规模 RL 泛化
强化学习扩展到百万级 Agent 环境,任务复杂度逐级递增,提升真实场景的适应能力。
④ 201 种语言支持
覆盖全球 95% 以上人口使用的语言和方言,真正做到全球化部署。
小模型(0.8B-9B)全部开源,可从 Hugging Face 或 ModelScope 下载。
二、Qwen-Image:中文生图终于有了有力竞争者
Qwen-Image 是一个 20B 参数的 MMDiT 图像基础模型,主打中英文文字渲染。
这件事值得单独说一下:AI 生图领域长期存在一个痛点——中文字符渲染失败。Stable Diffusion、DALL-E、Flux 生成中文都容易出现乱码、变形、错字。
Qwen-Image 在这方面做到了:
- 支持多行布局、段落级语义渲染
- 中文字符高保真,笔画结构正确
- 英文字母同样清晰精准

在 GenEval、DPG、OneIG-Bench 等生成 benchmark,以及 LongText-Bench、ChineseWord、TextCraft 等文字渲染 benchmark 上,Qwen-Image 均达到 SOTA。
可以在 Qwen Chat(chat.qwenlm.ai)的”Image Generation”功能里直接体验。
三、Qwen-Image-Edit:精准编辑,连字体都能改
Qwen-Image-Edit 基于 Qwen-Image 20B 底座,专门针对图片编辑任务优化。
核心能力:
语义编辑:改变图片内容和风格,同时保持原始语义一致性。比如把图片里的角色换装、换背景,人物特征完整保留。
外观编辑:精确修改像素级细节,只改要改的区域,其他部分完全不动。
文字编辑(亮点):支持中英文双语,可以直接修改图片中的文字,同时保持原有字体、大小和样式。这个能力在实际工作中极为实用——改海报文字、修宣传图、调整 UI 截图,不用重新设计。
技术上,Qwen-Image-Edit 同时将输入图片送入 Qwen2.5-VL(负责语义控制)和 VAE Encoder(负责外观控制),实现语义和外观的双重精准把控。
可在 Qwen Chat 的”Image Editing”功能体验。
横向对比:Qwen-Image-Edit vs Gemini 3 Pro Image vs GPT-4o Image
图片编辑这个赛道,目前三个模型最值得关注:Qwen-Image-Edit(阿里开源)、Gemini 3 Pro Image(Google,业内昵称 Nano Banana Pro)、GPT-4o Image(OpenAI,模型名 gpt-image-1)。
① 中文文字编辑能力
这是最核心的差异点。
Qwen-Image-Edit 天生就为中文而生——底座 Qwen-Image 本身就是全球中文文字渲染最强的生图模型之一,支持改字时完整保留原始字体、大小和样式。改海报标题、修宣传图文案,一句话指令搞定。甚至支持链式分步纠错:先框出要改的区域,再逐步精确修改,可以精确到某个笔画的偏旁部首。
Gemini 3 Pro Image 同样对中文支持出色,坐标定位精准,结合外部脚本可以先检测文字坐标、再精确替换,改后整体画面保真度高。
GPT-4o Image 支持中文,但中文字符的细节(笔画复杂度、字形还原)略弱于前两者,对英文和拉丁字母表现更稳定。
② 编辑能力范围
Qwen-Image-Edit 提供两种编辑模式,这是它独特的双通道架构带来的优势:
- 语义编辑:修改图片内容和整体风格,同时保持原始语义一致性。比如把角色换装、换背景、转换为吉卜力动画风格,人物特征完整保留。
- 外观编辑:精确修改像素级局部细节,只改要改的区域,其他区域完全不动。比如给场景添加招牌(还会自动生成倒影细节)、去除细碎发丝、只改某个字母的颜色。
技术上,它同时将输入图片送入 Qwen2.5-VL(负责语义理解和控制)和 VAE Encoder(负责外观像素控制),实现双重精准把控——这是 Qwen-Image-Edit 架构上最大的亮点。
Gemini 3 Pro Image 擅长局部文字替换、风格迁移和图片超分放大,改字后整体画面保真度很高,但语义编辑(如换装、风格转换)相对没有 Qwen-Image-Edit 那么细腻。
GPT-4o Image 是全功能选手:文字渲染、风格转换、局部编辑、图片修改都能做,并且因为图像生成是原生内置于 GPT-4o 而非外挂模块,模型能理解并利用对话上下文,在多轮交互中保持图像一致性。官方数据显示,它可以处理单张图里 10-20 个独立对象,并对每个对象的颜色、位置、状态精确控制。
③ 交互体验
| 对比维度 | Qwen-Image-Edit | Gemini 3 Pro Image | GPT-4o Image |
|---|---|---|---|
| 交互方式 | 单轮指令 / API / Qwen Chat | 两步流程(坐标检测 → 精确替换) | 对话式多轮迭代,跨轮一致 |
| 链式修改 | ✅ 支持逐步框区域纠错 | 需手动多次调用脚本 | ✅ 对话上下文自动衔接 |
| 改完后超分 | 暂无原生超分接口 | ✅ 支持 1K/2K/4K 超分输出 | ✅ 支持多种标准尺寸 |
| 开放程度 | ✅ 开源(HuggingFace 可下载) + 免费体验 | Google AI Studio 免费 | 付费 API |
④ 适用场景推荐
- 改中文海报/UI截图/宣传图文字 → Qwen-Image-Edit 首选,字体保留最完整,开源可本地部署
- 高精度坐标定位改字 + 输出要 2K/4K 高清 → Gemini 3 Pro Image,结合检测脚本定位更稳,超分效果好
- 创意类多轮迭代、需要自然对话修改、不在乎费用 → GPT-4o Image,体验最流畅,跨轮一致性最强
三个模型各有侧重,Qwen-Image-Edit 的亮点在于开源 + 中文专精 + 双通道架构,是目前开源图片编辑模型里能力最全面的之一。
四、Qwen3Guard:实时流式安全审核,业界首次
这是 Qwen 系列第一个安全护栏模型,用于检测 AI 输出内容是否安全。

两种变体:
- Qwen3Guard-Gen:离线模式,接受完整的用户 prompt 和模型回复,进行安全分类。适合数据集过滤、RL 奖励信号生成。
- Qwen3Guard-Stream(关键创新):实时流式检测,在模型逐 token 生成过程中同步审核,不需要等生成完毕。这是开源模型中首次实现此类能力,对生产环境的实时应用价值极大。
三种尺寸: 0.6B、4B、8B,适配不同资源场景。
支持中文、英文及多语言环境,在主流安全 benchmark 上达到 SOTA。阿里云也提供了基于 Qwen3Guard 的 AI Guardrails 商业服务。
五、Qwen-MT:92 种语言,机器翻译重新定义
Qwen-MT(qwen-mt-turbo)是基于 Qwen3 微调的翻译专用模型,通过 Qwen API 提供服务。
核心数据:
- 支持 92 种主要语言和方言
- 覆盖全球超 95% 人口
- 集成强化学习,显著提升翻译准确性和语言流畅度
这不是 Qwen3 套了个翻译 prompt——而是用数万亿多语言翻译 token 专门训练,加上 RL 对齐,是正经的翻译垂直模型。
总结:Qwen 在下一盘大棋
梳理完这五条产品线,可以看到一个清晰的战略:
| 模型 | 定位 |
|---|---|
| Qwen3.5 全系列 | 基础大模型,0.8B-397B 全覆盖 |
| Qwen-Image | 生图基础模型,中文文字渲染领先 |
| Qwen-Image-Edit | 图片精准编辑,文字改写 |
| Qwen3Guard | 安全审核,实时流式检测 |
| Qwen-MT | 92语言翻译专用 |
这不是”发模型蹭热度”,而是在构建一套从基础语言能力、多模态生成、内容安全、到垂直场景的完整 AI 基础设施。
每一个模型都在对应赛道争 SOTA,而且全部开源(API 商用版另行收费)。
对开发者来说,这波发布值得认真研究——你的下一个应用里,可能不止用到一个。


