OpenAI 买下 Python 工具链,大模型圈的"…
OpenAI 买下 Python 工具链,大模型圈的”基础设施争夺战”正式打响
📅 2026-03-20|约3200字|阅读约8分钟

这周 AI 圈最让我意外的消息,不是又一个”最强模型”发布,而是 OpenAI 宣布收购 Astral——那家做 uv、ruff、ty 的 Python 工具公司。
乍一看跟大模型没关系。但仔细想想,这可能是整个 AI 行业格局演变中最值得关注的信号之一:大模型公司开始把手伸向开发者基础设施。
一、本周大模型动态一览
| 事件 | 来源 | 重要性 |
|---|---|---|
| OpenAI 收购 Astral(uv/ruff/ty Python 工具链) | OpenAI 官博 | ⭐⭐⭐⭐⭐ |
| Mistral Small 4(119B MoE)开源发布,三合一能力 | HuggingFace + Mistral | ⭐⭐⭐⭐⭐ |
| Gemini 3.1 Flash-Lite 发布,$0.25/1M tokens | Google DeepMind | ⭐⭐⭐⭐ |
| NVIDIA Nemotron-3 Super 120B 开放权重发布 | NVIDIA | ⭐⭐⭐⭐ |
| Qwen3.5-397B 在 48GB MacBook 本地运行成功 | Simon Willison | ⭐⭐⭐⭐ |
| 智谱 GLM-OCR 开源,OmniDocBench 第一名 | 智谱 AI | ⭐⭐⭐⭐ |
| Mistral Forge:企业私有模型训练系统发布 | Mistral | ⭐⭐⭐ |
二、重点拆解
🔥 OpenAI 收购 Astral:这不只是一笔收购

3 月 19 日,OpenAI 官宣收购 Astral——这家公司的代表作是 uv(Python 包管理)、ruff(极速 linter)、ty(类型检查器)。如果你是 Python 开发者,这三个工具你多半都用过,或者即将用到。
这笔收购的本质是什么?
表面上,OpenAI 给出的理由是”加速 Codex 发展”。Codex 目前已有 200 万周活用户,今年以来用户增长 3 倍、用量增长 5 倍。Astral 的工具链恰好覆盖了 AI 编程助手最需要的工作流节点:依赖管理、代码质量、类型安全。
但更深层的逻辑在于:**OpenAI 要把自己变成 Python 开发者生态的”基础设施提供商”**。
想象一下未来的场景:你用 uv 装包,用 ruff 格式化,用 ty 做类型检查,然后用 Codex 补全代码——整条链路都是 OpenAI 的产品。这不是简单的 AI 工具,而是整个开发者工作流的入口。
Simon Willison 在博客里写得很直接:”Astral 的工具是 Python 生态系统的负重基石(load-bearing infrastructure)。”这也是他对这笔收购最大的担忧所在——一个商业公司突然控制了大量开发者依赖的开源工具,会发生什么?
OpenAI 承诺会继续维护开源。我们只能拭目以待。
🚀 Mistral Small 4:一个模型顶三个,119B MoE 开源

3 月 17 日,Mistral 发布 Mistral Small 4(119B 参数,MoE 架构),Apache 2.0 开源。这次发布有个很有意思的设计:把三种能力合并到一个模型里——指令跟随(Instruct)、推理(Reasoning/Magistral)、代码(Devstral)。
核心参数:
- 119B 总参数,每个 token 激活 6.5B(128 个专家,每次选 4 个)
- 256k 上下文
- 多模态:支持图片+文本输入
- 延迟优化版:端到端完成时间减少 40%
- 吞吐量优化版:每秒请求量是 Small 3 的 3 倍
- 推理模式可按需开关(
reasoning_effort="high"/"none")
这个设计思路挺有代表性的:过去你要用推理模型就切 o1/QwQ/Magistral,要用代码模型就切 Devstral,要用快速对话就切 Small 3。现在 Mistral 说:不用换了,我一个模型全搞定。
对于自部署用户来说,这个性价比非常吸引人。119B MoE 实际激活量约等于 6.5B 密集模型,算力需求远低于参数量暗示的水平。
⚡ Gemini 3.1 Flash-Lite:每百万 token 只要 0.25 美元

3 月 3 日,Google 发布 Gemini 3.1 Flash-Lite,定价 $0.25/1M input tokens,$1.50/1M output tokens。
这个价格有多离谱?对比一下:
- 比 2.5 Flash 快 2.5 倍(Time to First Token)
- 输出速度提升 45%
- Arena.ai ELO 得分 1432
- GPQA Diamond:**86.9%**(超过部分前代大号模型)
- MMMU Pro:76.8%
Flash-Lite 的定位是”大规模开发者工作负载”——翻译成人话就是:如果你要做内容审核、批量翻译、大量数据处理,这是目前性价比最高的选项之一。
内置可调节 thinking levels,开发者可以按任务复杂度控制推理深度。这对高频低延迟场景非常有用。
🤖 NVIDIA Nemotron-3 Super:1M context + 创新混合架构

3 月 11 日,NVIDIA 开放 Nemotron-3 Super 120B 权重。这个模型的亮点不是参数量,而是架构创新:
LatentMoE = Mamba-2 + MoE + Attention 混合
具体来说,模型的大部分层使用 Mamba-2(线性时间复杂度的状态空间模型),只在少数关键位置插入标准 Attention 层。这种设计的好处是:在超长上下文下,Mamba-2 的推理成本随序列长度线性增长,而不是传统 Transformer 的平方级增长。
结果是 1M token 上下文——这在 120B 量级的开放权重模型里前所未有。
另外还有 Multi-Token Prediction(MTP)层,可以在一次前向传播中预测多个 token,加速生成。
用途:IT 工单自动化、超长文档分析、复杂 Agentic 工作流。最低硬件要求 8×H100-80GB,面向企业部署场景。
💻 397B 大模型跑在 MacBook 上:SSD 流式推理的新可能
这周 Simon Willison 博客里转发了一个实验:研究员 Dan Woods 成功在 48GB MacBook Pro M3 Max 上运行 Qwen3.5-397B-A17B——这个模型磁盘上占 209GB(4-bit 量化)。
核心技术来自苹果 2023 年的论文”LLM in a Flash”:把模型参数存在 SSD,只把当前需要的 expert 权重动态载入内存。对 MoE 模型来说,每次只激活一小部分专家,非常适合这种流式加载模式。
Dan 用了 Claude Opus 4.6 + Andrej Karpathy 的 autoresearch 方法,跑了 90 次实验,最终生成 MLX Metal 代码,速度达到 4.36 tokens/秒(4-bit 量化版)。
4 tokens/秒听起来不快,但别忘了这是 397B 的模型,在只有 48GB 内存的消费级 Mac 上。对于离线分析、隐私敏感场景,这种方案的价值不可忽视。
关键验证点:4-bit 量化版工具调用能力正常(2-bit 版 tool calling 会出问题)。
🇨🇳 国内亮点:GLM-OCR 开源,OmniDocBench 登顶
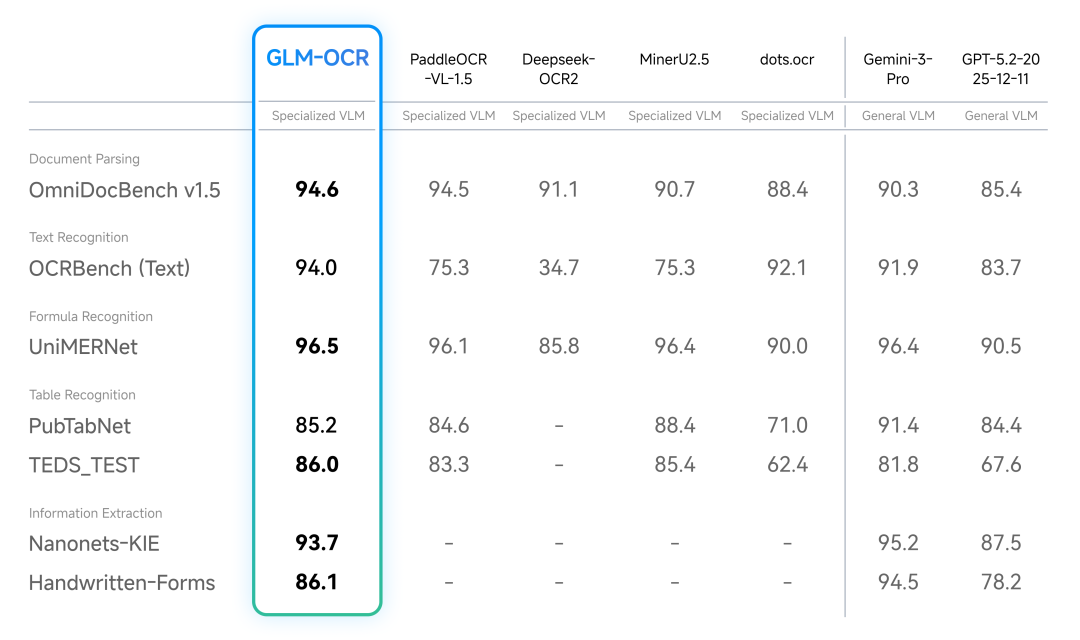
智谱 AI(zai-org)本周开源了 GLM-OCR,在 OmniDocBench V1.5 上拿到 94.62 分,排名第一。
GLM-OCR 的设计很务实:
- 只有 0.9B 参数,但专为文档理解优化
- 架构:CogViT 视觉编码器 + 轻量跨模态连接器 + GLM-0.5B 语言解码器
- 支持 vLLM / SGLang / Ollama 部署
- 专长:复杂表格、含代码文档、印章、多列布局
百度也同期开源了 Qianfan-OCR(5B 参数),两家国内公司在文档理解这个垂直赛道上直接 PK。
OCR 看起来不性感,但它是企业文档数字化、合同解析、发票处理的核心基础。国内厂商在这块做到世界第一,是实实在在的产业价值。
三、这周在说一件什么大事?
AI 公司的竞争边界正在从”模型能力”扩展到”开发者生态”。
几个信号叠在一起:
- OpenAI 买工具链——Codex 不只是代码补全,而是要成为开发者的”操作系统”
- Mistral 推 Forge——让企业在自己的数据上训练”私有前沿模型”,直接挑战云厂商 fine-tune 业务
- Google 的价格战——Flash-Lite $0.25/1M 在疯狂压缩中间层 API 商的利润空间
这三件事有一个共同主题:大模型公司在争夺开发者,而不只是用户。因为开发者是乘数效应的来源,开发者用你的工具,就会有百倍的终端用户用到你的模型。
微软当年靠 Visual Studio + .NET 锁定开发者,OpenAI 现在在做的事情,有几分相似的味道。
唯一的区别是:这次的工具是开源的。开源是护城河,还是特洛伊木马?各家公司都还没给出答案。
如果觉得有价值,欢迎转发给也在关注 AI 的朋友。下周见。
— 张铁,每周五更新


