大模型后训练,究竟在训练什么?
大模型后训练,究竟在训练什么?
你有没有想过,ChatGPT、Claude、Qwen 这些 AI 助手,是怎么从”只会预测下一个字”变成”会和你聊天、帮你写代码、拒绝回答有害问题”的?
答案只有两个字:后训练。
今天这篇文章,不讲数学公式,只讲清楚一件事:大模型后训练到底是什么,不同类型的模型又是怎么训练的。
一、先搞清楚:预训练 vs 后训练
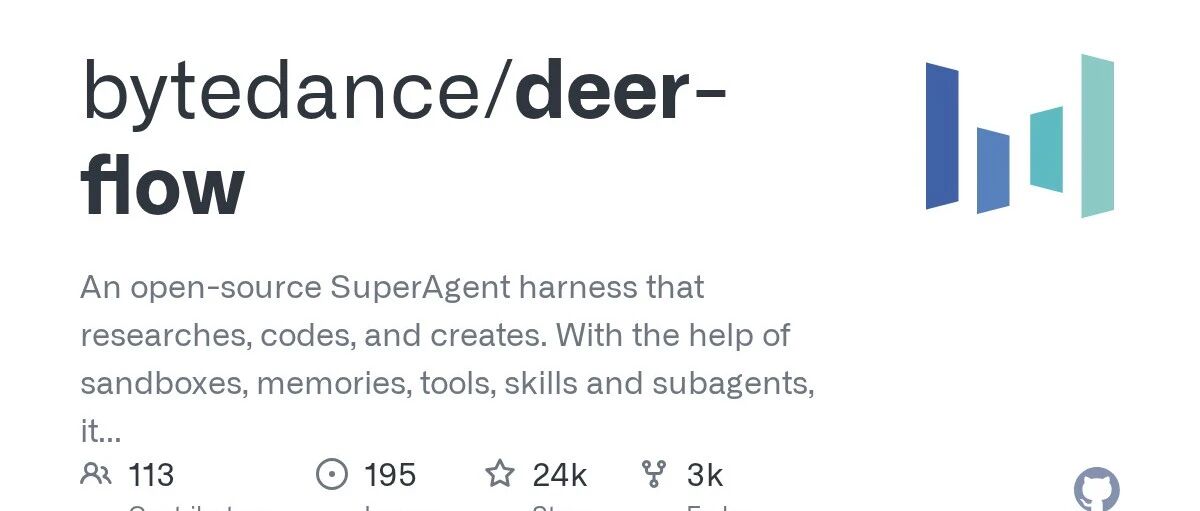
要理解后训练,先得知道它的前一步——预训练。
打个比方:
预训练,就像一个人从小到大读了几万本书、刷了几十亿网页,学会了语言、积累了海量知识。
但读完书的人,不一定会”做事”——他可能说话啰嗦,可能回答问题前先背一遍原文,可能被人一激就说出不该说的话。
后训练,就是把这个”读了很多书的人”训练成一个”靠谱的助手”的过程。
具体来说:
- 预训练:用几万亿字的文本,让模型学会”预测下一个词”
- 后训练:用精心设计的数据和奖励,让模型学会”怎么帮人做事”
预训练决定模型知道多少,后训练决定模型用起来好不好用。
二、后训练的三种主要方法
方法一:SFT(监督微调)——给模型示范答案
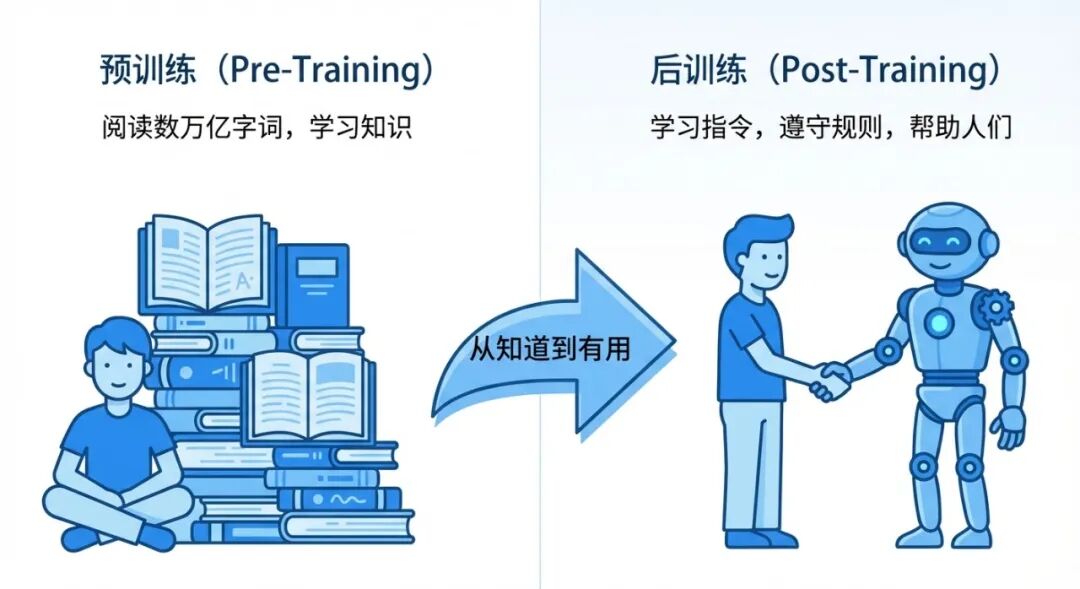
SFT 的全称是 Supervised Fine-Tuning,意思是”有监督的微调”。
类比: 想象你培训一个新员工,最简单的方法就是给他一堆”问题 + 标准答案”,让他反复学。学会了之后,遇到类似的问题,他就能给出像样的回答。
具体怎么做:
- 由人类专家(或更强的模型)写出高质量的”对话示例”
- 把这些数据喂给模型
- 模型学着模仿这些示例的风格和内容
SFT 是后训练的基础,几乎所有 AI 助手都会先做这一步。它的优点是直接、可控;缺点是需要大量高质量的标注数据,而且模型只能”学样子”,不一定真正理解为什么这样回答更好。
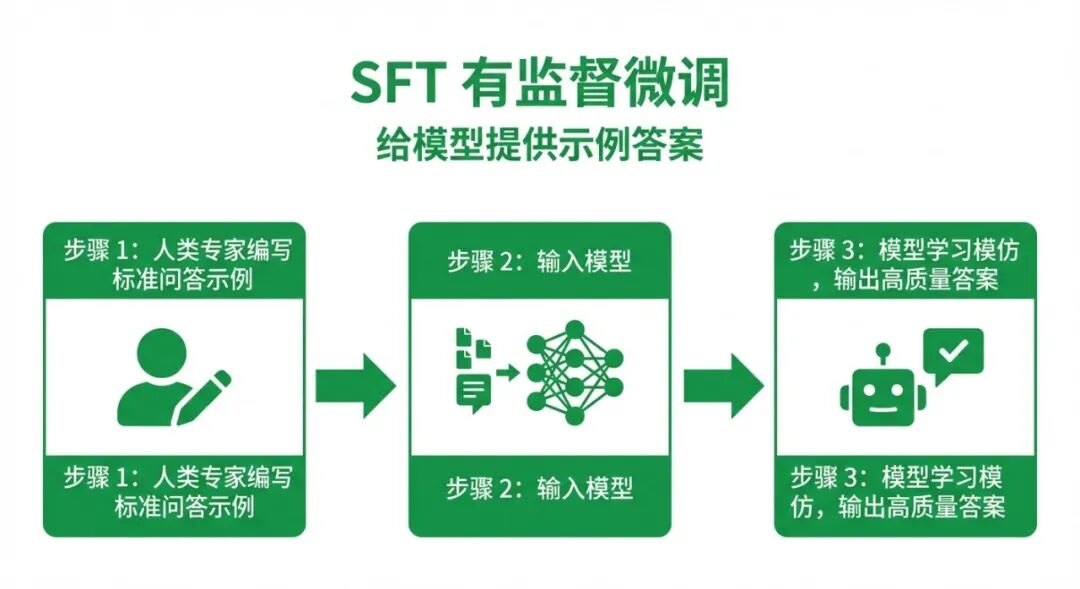
方法二:RLHF(人类反馈强化学习)——让人类来打分
RLHF 是 Reinforcement Learning from Human Feedback 的缩写,ChatGPT 就是靠这个方法变好用的。
类比: 新员工(模型)做完工作后,让主管(人类标注员)给他的答案打分,评价哪个回答更好。员工根据这些反馈,不断调整自己的行为,争取下次得到更高分。
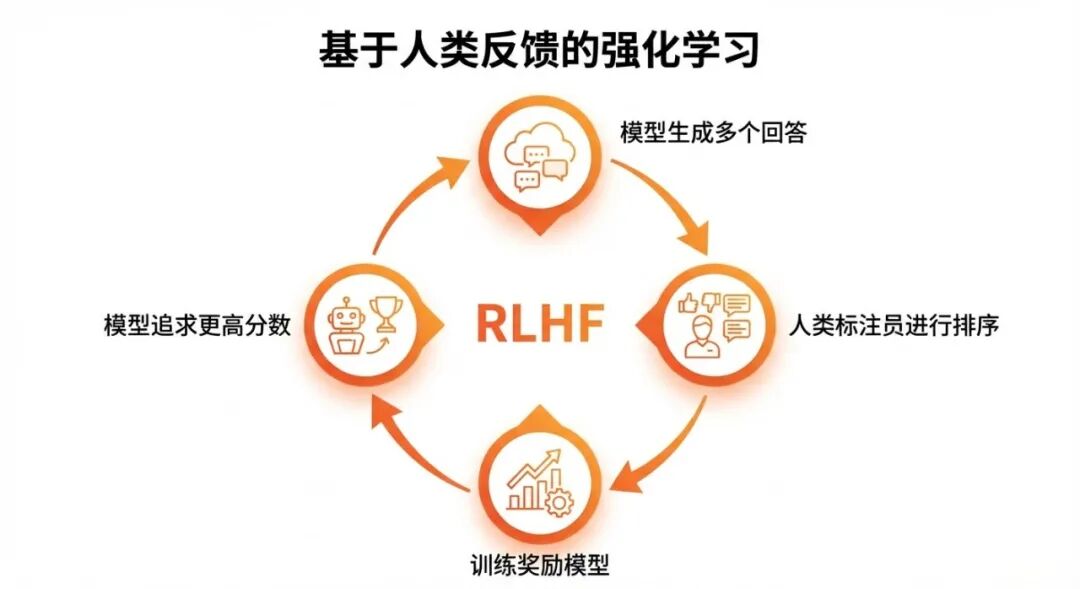
具体步骤:
- 模型生成多个回答
- 人类标注员对这些回答进行排名(哪个更好)
- 用这些排名数据训练一个”奖励模型”——专门负责给回答打分
- 让原始模型不断优化,追求更高的分数
RLHF 的强大之处在于,它能捕捉到很难用文字表达的”人类偏好”——比如回答要有帮助、无害、诚实。这正是 OpenAI 提出的 HHH 原则(Helpful、Harmless、Honest)。
方法三:DPO(直接偏好优化)——更省力的替代方案
DPO 是 Direct Preference Optimization,2023 年由斯坦福提出,是 RLHF 的简化升级版。
类比: RLHF 相当于”先找一个评委,再让选手根据评委反馈不断练习”——流程长、成本高。DPO 则直接告诉模型”A 比 B 好”,让模型从对比中直接学,省掉了中间那个奖励模型。
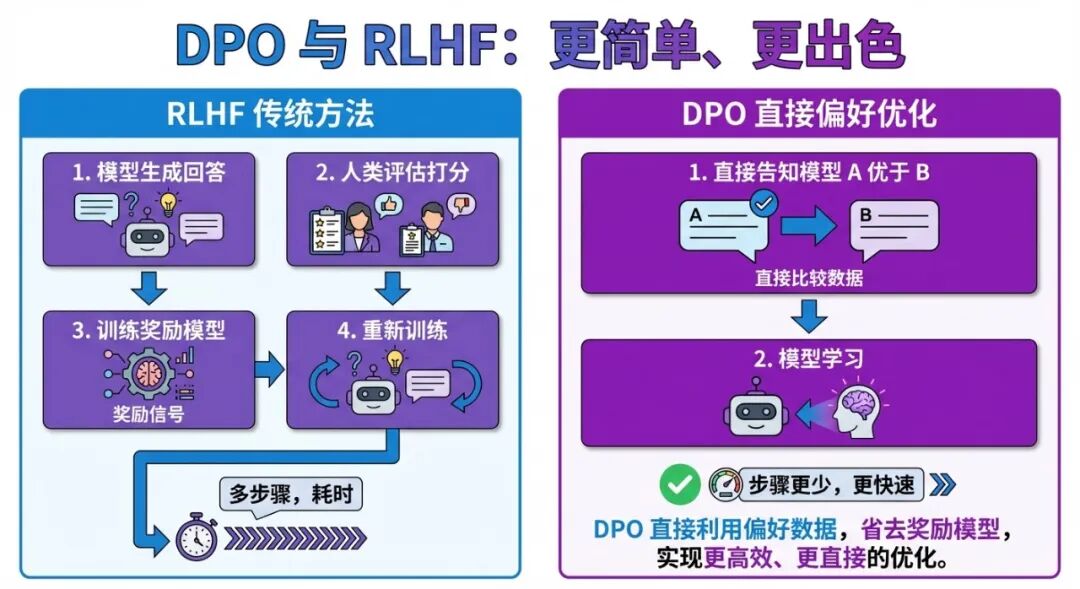
DPO 的好处是训练更稳定、计算成本更低,现在越来越多的模型在用。
三、不同类型的模型,后训练重点大不同
重点来了。后训练不是一个固定的流程,不同用途的模型,后训练的侧重点完全不一样。
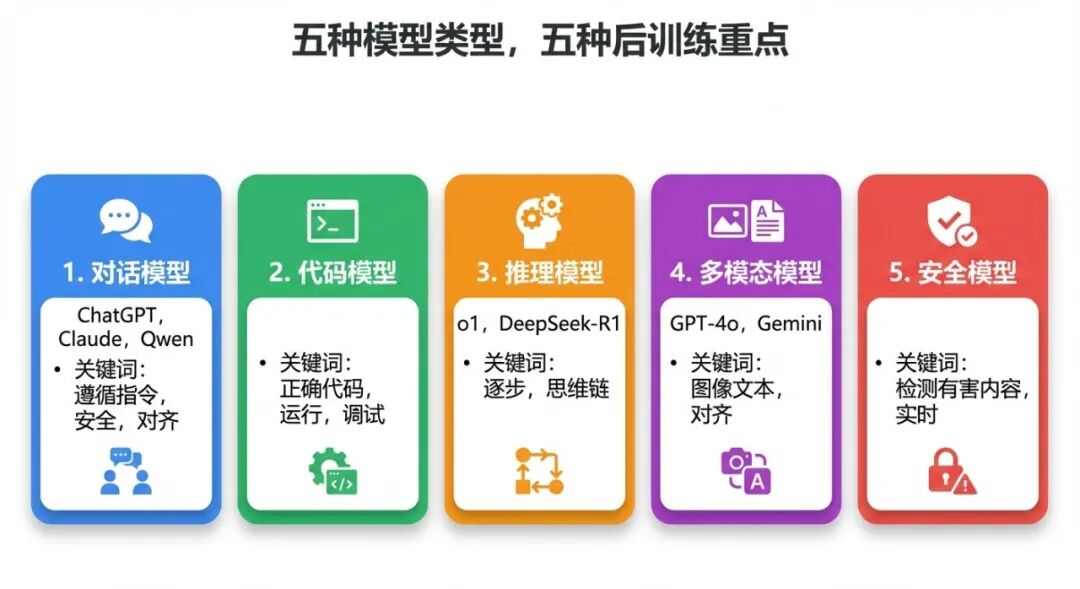
对话模型:ChatGPT、Claude、Qwen
目标: 听懂指令、有帮助、拒绝有害内容、不撒谎
这类模型是后训练研究最成熟的领域。训练数据涵盖各种日常对话、写作、问答场景,大量使用 RLHF 和 DPO 让模型”懂规矩”。
重点训练的能力:
- 遵循指令(你让它列清单,它不要写段落)
- 安全对齐(遇到有害问题要拒绝)
- 有帮助但不谄媚(不能只会说”好的!当然!”)
代码模型:DeepSeek-Coder、Codex
目标: 写出能跑通的代码,还要能 debug
代码模型的后训练有个天然优势:代码对不对,运行一下就知道。 这个特性让强化学习变得特别好用——把”代码执行成功”作为奖励信号,模型会自动学会写更好的代码。
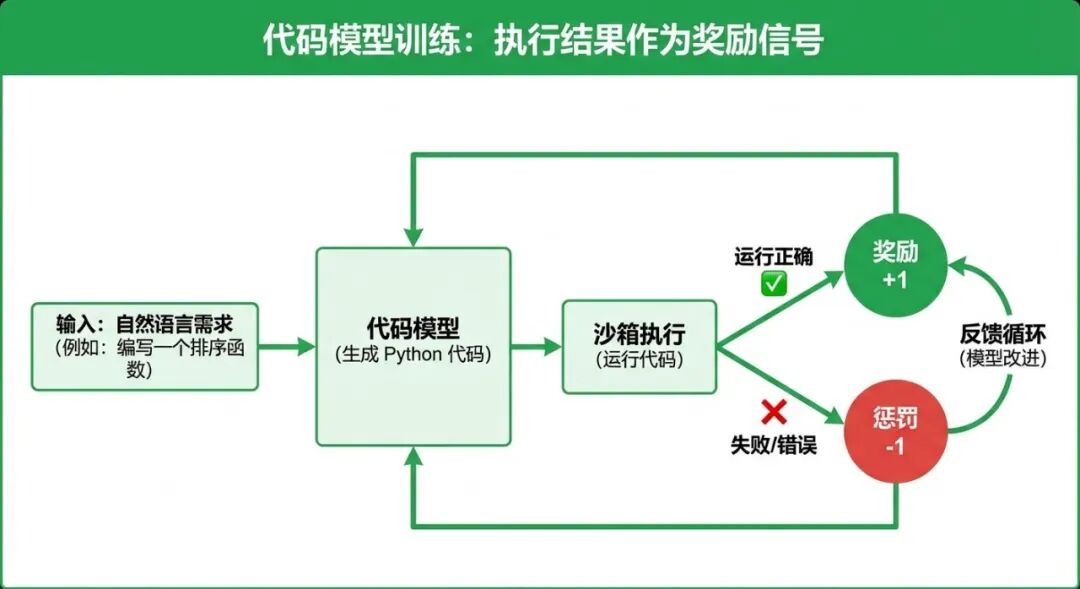
重点训练的能力:
- 代码逻辑正确(不只是语法对)
- 理解需求(把自然语言需求转换为代码)
- 多语言支持(Python / JS / Go / Rust 等)
推理模型:o1、DeepSeek-R1、QwQ
目标: 一步一步想清楚,解决复杂数学和逻辑题
这是近两年最热的方向。推理模型的核心思想是:**让模型在回答前先”想一想”**,就像人做数学题时会打草稿一样。
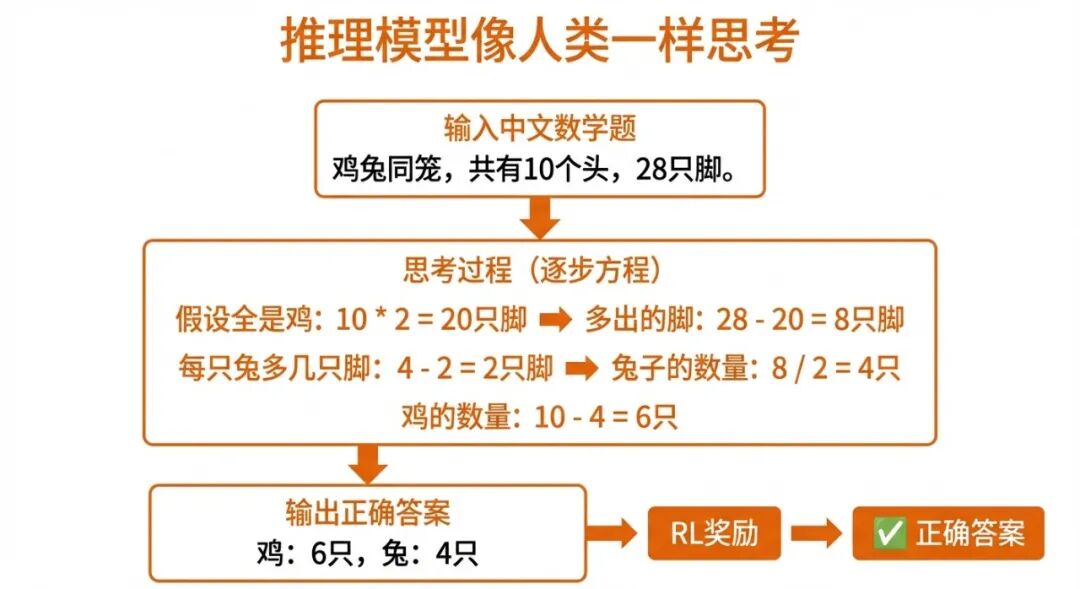
训练方法:
- 大规模强化学习:给模型大量数学题、逻辑题,答对了就奖励
- 链式思维(Chain-of-Thought)数据:教模型展示解题过程
- 关键发现:当 RL 规模足够大时,模型会自发学会反思和纠错(这是 DeepSeek-R1 最震惊业界的发现之一)
OpenAI 的 o1 系列就是靠这套方法,在数学和编程竞赛题上超越了人类专家水平。
多模态模型:GPT-4o、Gemini、Qwen3.5
目标: 同时看懂图、听懂音频、读懂文字
多模态模型的后训练面临一个额外挑战:图文对齐——模型不仅要理解文字,还要理解图片内容,并把两者关联起来。
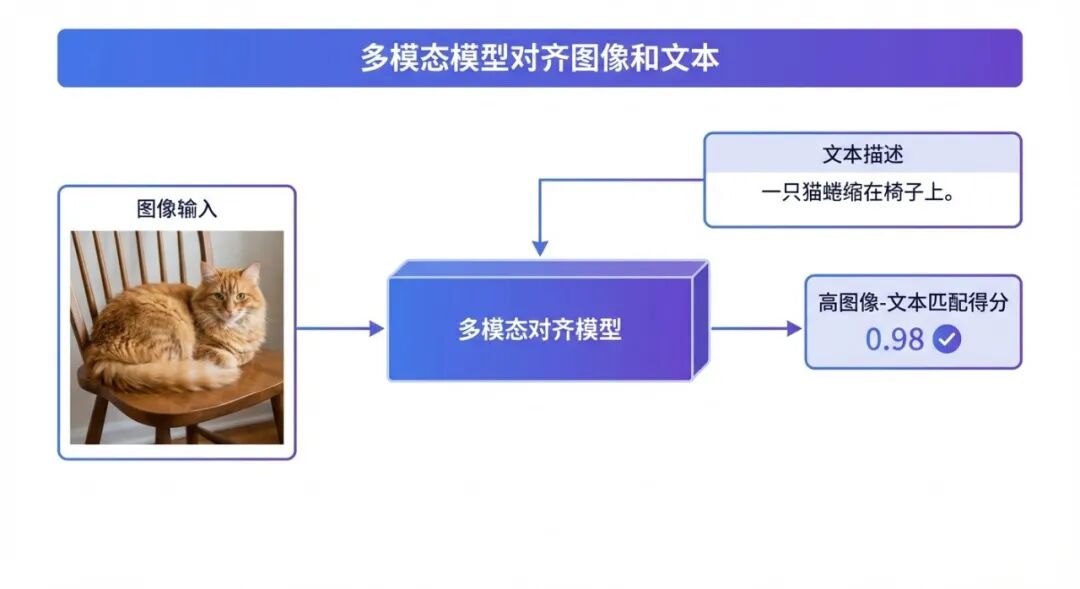
重点训练的能力:
- 图像描述准确(看图说话)
- 图文问答(看着图回答问题)
- 视觉指令跟随(”帮我把图里的文字翻译一下”)
Qwen3.5 的原生多模态融合,就是在预训练阶段就同时处理图文 token,后训练阶段再进一步对齐,这比”先训文字模型再插入视觉模块”的方式效果更好。
安全模型:Qwen3Guard、Llama Guard
目标: 准确判断内容是否安全,不误判、不漏判
安全模型是一类特殊的后训练产物,它的工作不是聊天,而是当裁判——判断其他模型的输出是否有害。
训练数据: 大量人工标注的”安全 / 不安全”对话样本,覆盖暴力、色情、歧视、虚假信息等多个类别。
主要用 SFT 训练,追求的是分类准确率。Qwen3Guard-Stream 更进一步,实现了流式实时检测——不用等模型说完,生成过程中就能拦截有害内容。
四、后训练的三个未来趋势
数据质量 > 数据数量
以前大家觉得”数据越多越好”。现在的共识是:1000 条高质量数据,比 100 万条劣质数据更有用。 如何筛选、合成高质量的后训练数据,成了各家模型厂商竞争的核心秘密。
强化学习越来越重要
o1 和 DeepSeek-R1 证明了:当强化学习规模足够大、奖励信号足够清晰,模型能涌现出”会自主思考”的能力。未来更多类型的任务(写作、科研、代码)都会引入 RL。
少样本对齐
用越来越少的标注数据,训出越来越好的对齐效果——这是成本与效果的博弈,也是让 AI 更容易被更多人部署的关键。
总结
一句话总结:预训练给了模型”知识”,后训练给了模型”做事的能力和规矩”。
不同类型的模型,后训练的目标不同,方法也不同:
- 对话模型 → RLHF + DPO,重点对齐人类偏好
- 代码模型 → 执行结果作为奖励信号
- 推理模型 → 大规模 RL,奖励答对
- 多模态模型 → 图文对齐联合训练
- 安全模型 → SFT 分类,实时拦截
AI 发展这么快,不是因为模型越来越”大”,而是因为后训练让它们越来越”聪明”、越来越”好用”。
这才是大模型军备竞赛真正的战场。